Недоступность в картинках
Когда мы говорим про доступность, мне часто не хватает визуальной составляющей. «Недоступно для скринридера» — как это выглядит?
Когда есть возможность запустить программу экранного доступа и увидеть всё своими глазами, это достаточно освежающий опыт, после которого начинаешь гораздо аккуратнее выбирать теги. Мне хотелось бы, чтобы это попробовал каждый, кто имеет дело с вёрсткой, но я подозреваю, что, хотя многие слышали о доступности и скринридерах, запускать читалку пробовали далеко не все — потому что надо не только найти где включается скринридер, но и разобраться в непривычном и достаточно неинтуитивном интерфейсе.
Я не так часто запускаю скринридер, и каждый раз приходится вспоминать команды и привыкать заново. Вообще попытка разобраться в настройках скринридера даже для зрячего требует усилий, а как с ними разбирается слабовидящий пользователь — страшно представить (а после этого человек заходит в интернет и попадает на сайты, где его никто не ждёт).
Я думаю, что каждому, кто имеет дело с вёрсткой, стоит попробовать читать страницы скринридером, потому что недоступность страниц лучше один раз увидеть, чем сто раз услышать. Ниже мы посмотрим как можно можно проверить веб-страницы с помощью скринридеров и узнаем на что обратить внимание при тестировании.
В данный момент встроенные программы экранного доступа есть и в MacOS (VoiceOver), и в Windows (Narrator). Есть и другие приложения, например, NVDA и JAWS, но для первого знакомства со скринридером проще воспользоваться тем, что у же есть в вашей операционной системе.
По VoiceOver и Narrator есть официальная документация:
- Полное руководство по использованию экранного диктора (Narrator)
- Универсальный доступ Apple: краткое руководство по VoiceOver
По ссылкам очень много текста, но нам достаточно небольшого количества команд.
Команды VoiceOver (MacOS)
Запуск и настройка
Для запуска VoiceOver нажмите Cmd + F5. После этого можно переключиться на окно браузера и попробовать прочитать страницу.
Если требуются дополнительные настройки, это можно сделать в Системные настройки/Универсальный доступ, и ещё больше настроек там же в подразделе Утилита VoiceOver.
Все команды для VoiceOver вводятся с сочетанием клавиш VO: Control + Option или Caps Lock.
Последовательный переход между элементами страницы:
VO + ←— перейти к предыдущем элементуVO + →— перейти к следующему элементу
Запуск чтения сверху вниз:
VO + A— чтение текста начиная с текущего положения на странице
Взаимодействие с DOM-элементами:
VO + Shift + ↓— начать взаимодействовать с элементом («провалиться» в него)VO + Shift + ↑— закончить взаимодействовать с элементом («вынырнуть»)
«Взгляд сверху»:
VO + U— открыть ротор
Последняя команда — самая интересная: она показывает все ориентиры и заголовки страницы, все ссылки и инпуты. Можно сразу перейти в нужный раздел, как по содержанию бумажной книги, пройтись по ссылками или перемещаться по элементам формы.
Команды Narrator (Windows)
Запуск и настройка
Чтобы запустить экранный диктор, одновременно нажмите Windows + Ctrl + Enter.
Панель настроек: Windows + Ctrl + N
По умолчанию клавишами экранного диктора назначены клавиши Caps Lock и Insert (далее ЭД).
ЭД + F1— справка по командам скринридера
Последовательный переход между элементами страницы:
ЭД + ←— перейти к предыдущем элементуЭД + →— перейти к следующему элементуЭД + Page Up/ЭД + Page Down— переключение режима перехода между элементами: переходить между словами, предложениями, ссылками, ориентирами или элементами формы.
Запуск чтения сверху вниз:
ЭД + ↓— начать чтение с текущего местаЭД + ↑илиCtrl— остановить чтение
«Взгляд сверху»:
ЭД + S— прослушать сводку по странице (количество ссылок, ориентиров и заголовков)двойное нажание
ЭД + Sоткроет диалоговое окно с этими даннымиЭД + F5— посмотреть список ориентировЭД + F6— посмотреть список всех заголовков на страницеЭД + F7— посмотреть список всех ссылок
Эти команды — примерный аналог ротора в VoiceOver. Хоткеи есть только для этих разделов, но из них можно попасть в другие.
Имея по рукой читалку и команды, можно отважно запустить скринридер и попробовать читать сайты.
Важно: перед запуском скринридеров убедитесь, что у интересующих вас страниц корректно указан язык (например, <html lang="ru">), и что язык, на котором вы планируете читать текст, есть в системе. Например, если вы хотите прочитать текст на русском, но его нет в операционной системе, скринридер может начать читать русский текст по одной букве, озвучивая перед каждой что это cyrillic letter. Возможно, перед использованием читалки потребуется немного покрутить настройки.
Можно начать читать прямо эту страницу или любую другую, но для более глубокого понимания в чём состоит разница между плохой и хорошей разметкой я создала проект, в котором есть оба этих варианта: A11y демо.
Доступная и недоступная страницы визуально ничем не отличаются:

Разница видна только в коде страницы, но для скринридеров эта разница значительна.
Недоступная версия свёрстана так, как если бы разработчик подумал «Какая разница какие теги? Добавлю CSS, и будет выглядеть как надо». Дивы вместо заголовков, вместо списков, кнопок — вместо всего. Зрячему пользователю практически без разницы что там в коде, но для слабовидящих воспользоваться такой страницей будет проблематично.
Ниже будут показаны примеры как именно скринридер видит (или не видит) разные варианты разметки. При чтении страницы VoiceOver дублирует произносимый текст в отдельном попапе, и именно он будет на скриншотах.
Скриншоты помогут понять что и как скринидер может не найти на странице, если полениться сверстать правильно, и подскажут на что обратить внимание, если вы отважились запустить скринридер и почитать страницы самостоятельно.
В примерах ниже все скриншоты будут с VoiceOver. Интерфейс Narrator, конечно, отличается, но структуру страницы они показывают примерно одинаково.
Куда смотреть?
Как мы обычно ориентируемся на веб-страницах? Сканируем глазами крупные элементы и заголовки, обращаем внимание на формы и ссылки. Скринридеры тоже так умеют: и VoiceOver, и Narrator умеют показывать заголовки, ссылки и интерактивные элементы.
Заголовки
Чтобы увидеть какие заголовки доступны читалке, выполните команды:
- Narrator:
ЭД + F6 - VoiceOver: откройте ротор
VO + Uи стрелками пролистайте до раздела с заголовками
Если на странице нет тегов H1-H6, в разделе может быть пусто или его может не быть вовсе.
Для версии с плохой разметкой список заголовков будет выглядеть вот так:

На странице есть только один настоящий заголовок (H1), все прочие заголовки — просто дивы с соответствующими стилями.
С такого заголовка можно попасть только в шапку сайта. На странице есть много других разделов, но для быстрой навигации они недоступны.
На странице с хорошей разметкой в роторе будут представлены все заголовки:

Можно выбрать нужный заголовок и сразу перейти в соответствующий раздел — это как в содержании книги найти нужную главу. Без оглавления пришлось бы листать всю книгу, а в случае с сайтом — прослушать весь сайт сверху вниз.
Если структура страницы подразумевает заголовок, но по макету его нет, добавьте его в разметку и скройте с помощью .visually-hidden:
.visually-hidden {
position: absolute;
width: 1px;
height: 1px;
margin: -1px;
border: 0;
padding: 0;
clip-path: inset(100%);
clip: rect(0 0 0 0);
overflow: hidden;
}
Почитать про этот способ можно здесь.
Обычные посетители не заметят разницы, а пользователи скринридеров получат возможность быстро попадать в любой раздел страницы.
Важно не только использовать H1-H6, но и формировать с их помощью иерархическую структуру документа. Это позволит даже на слух понять что во что вложено и как разделы страницы соотносятся друг с другом.
Уровни заголовков не про дизайн, не про размер шрифта — они про иерархию документа. Не важно какого размера шрифты на макете — с помощью CSS можно сделать любому элементу любой шрифт. Поэтому если вы видите на макете мелкий шрифт там, где по логике документа должен быть H1 или крупный там, где по уровню получается H4, выбирайте уровень заголовка исходя из иерархической структуры документа, а нужный размер шрифта задаётся стилями.
Проверить иерархию заголовков можно на validator.w3.org/nu/, поставив галочку Outline, отчёт появится внизу страницы:

Также проверить заголовки можно в генераторе HTML-дерева:

Правильное использование уровней заголовков, помимо всего прочего, облегчает выбор нужного тега H1-H6: когда у вас есть чёткое представление о структуре документа, вы сразу будете знать где какой тег должен быть. Это очень удобно.
Ориентиры
Ориентиры с точки зрения скринридера — это элементы main, aside, nav и article — главное содержимое страницы, дополнительное, навигация и статьи. Narrator также считает ориентирами header и footer.
Чтобы увидеть какие ориентиры нашёл скринридер, выполните команды:
- Narrator:
ЭД + F5 - VoiceOver: откройте ротор с
VO + Uи стрелками пролистайте до раздела с ориентирами
Предположим, разработчик не знал об этих тегах либо решил, что без разницы какие использовать. Получится такое:

Скринридер не обнаружил на странице никаких осмысленных элементов. Проблема та же, что и с заголовками: если ротор не показывает ориентир, пользователь не сможет быстро перейти к нужному разделу, а то и вовсе не узнает о его существовании.
А вот так будут выглядеть ориентиры, если использовать теги по назначению:

Не всё переведено, но, по крайней мере, можно примерно понять, что есть на странице, и перейти к нужному элементу.
Описание навигаций сделано с помощью aria-label. Это позволит отличать элементы навигации друг от друга, если их несколько на странице и у них разное содержимое.
Элемент main позволит пользователю скринридера сразу перейти к основному содержимому страницы, минуя шапку и верхнее меню. Вам ничего специально не нужно для этого делать, кроме как использовать правильный тег.
Формы
Формы используются на веб-страницах для самых разных целей. Скринридеры умеют читать элементы форм, и, если всё сделано правильно, пользователь сможет заполнить форму даже не видя её глазами.
Сможет купить билет, оформить документы или сделать заказ в интернет-магазине — при условии, что разработчик не поленился и сделал всё как надо. А если поленился, что тогда?
Чтобы увидеть какие элементы формы нашёл скринридер, выполните команды:
- Narrator:
ЭД + F5, затем в нижнем меню выберите Поля формы - VoiceOver: откройте ротор с
VO + Uи стрелками пролистайте до раздела с элементами управления
Откроем ротор на странице с плохом примером:

Скринридер нашел несколько радиокнопок и чекбокс без описаний. Что делают все эти инпуты — совершенно непонятно.
Иногда на странице с плохом примером скринридер может показывать в качестве лейблов ближайший текст, но это поведение нестабильно. Кроме того, скринридер может подставлять не тот текст. Если перемещаясь по странице несколько раз открыть ротор, можно поймать разные варианты подписей к инпутам.
А вот как выглядит форма на самом деле:
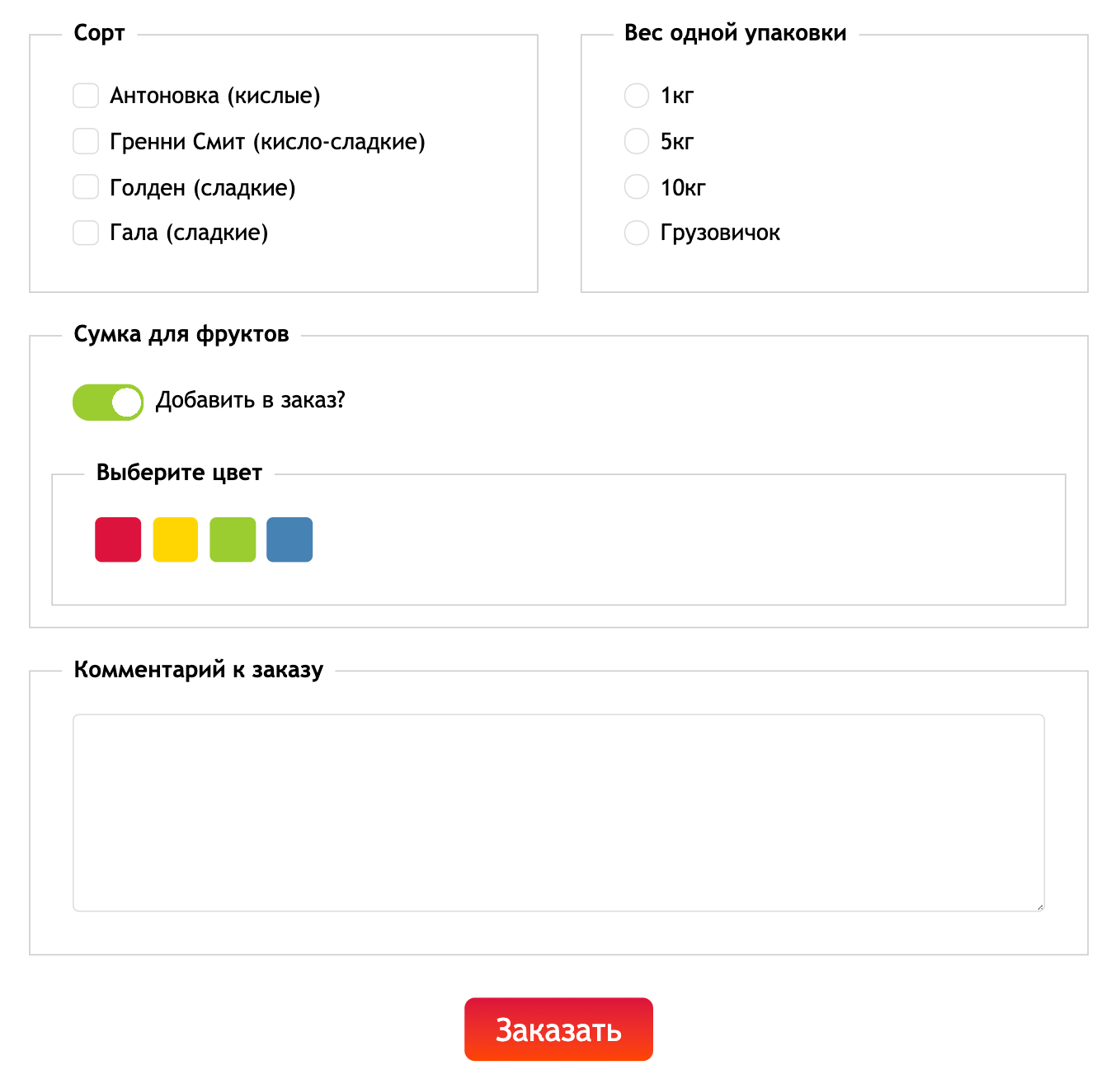
В роторе потерялась половина инпутов и кнопка «Заказать», у оставшихся нет подписей.
В плохом примере можно увидеть несколько распространенных ошибок:
- инпуты скрыты с помощью
display: none(в группе Сорт) - у инпутов нет лейблов (в группе Вес одной упаковки)
- в лейблах нет текста (в выборе цвета)
divвместоbuttonу кнопки отправки формы
display: none
Во-первых, скрытие инпутов с помощью display: none убирает их со страницы полностью — и визуально, и для скринридеров. Пользователь скринридера не сможет попасть на них никаким образом. На скрине ротора выше видно, что там представлены только радиокнопки с выбором веса и цвета, а чекбоксов с сортами просто нет. Если читать страницу сверху вниз, скринридер честно прочитает подписи к чекбоксам, но сами чекбоксы для него отсутствуют полностью.
Во-вторых, использование display: none создает проблемы при навигации с клавиатуры, потому что лишает возможности попасть на эти инпуты переходя по табу. С точки зрения браузера их вообще нет на странице, поэтому переход по табу просто проигнорирует эту группу инпутов. Зрячие пользователи всё ещё могут выбирать чекбоксы кликая по лейблам, но с помощью Tab это сделать не получится, придётся кликать вручную.
Чтобы скрыть инпуты, сохранив их доступными для скринридеров и навигации с клавиатуры, используйте класс .visually-hidden. Так они будут доступны для всех пользователей.
Лейблы для инпутов
Отсутствие лейблов также является серьёзной проблемой. Инпуты доступны для скринридера, к ним можно перейти, но что они делают — совершенно непонятно:

Пользователь может попытаться ориентироваться по окружающему тексту, но так можно запутаться что за чем идёт и выбрать не тот инпут, к которому относится текст. Чтобы избежать путаницы, имеет смысл всегда всем инпутам привязывать лейблы с текстовым описанием.
Лейблы делают форму удобнее и для зрячих пользователей: когда есть лейблы, можно кликнуть по тексту лейбла, а не целиться по инпуту. Сравнить такое поведение можно в плохом примере: чтобы выбрать сорт, достаточно кликнуть по тексту, чтобы выбрать вес — придётся целиться по радиокнопке, что очень неудобно.
Привязать лейбл к инпуту можно через атрибут for:
<label
for="input-1">
Красные яблоки
</label>
<input
type="checkbox"
id="input-1"
value="product-1"
>
Или вот так, вложив инпут в лейбл:
<label>
Красные яблоки
<input
type="checkbox"
id="input-1"
value="product-1"
>
</label>
Оба способа работают одинаково, так что без разницы какой выбирать. Главное — не забывать добавлять лейблы для всех инпутов на странице.
Лейблы без текста
Даже если лейблы есть, и они привязаны к инпутам, отсутствие в них текста делает их совершенно бесполезными для пользователей скринридеров. Как мы видели на скрине выше, в роторе такие инпуты будут показаны без описаний, а если перейти непосредственно к инпуту, скринридер покажет это:

А так как рядом нет совсем никакого текста, у пользователя скринридера не будет никаких шансов понять что ему предлагается тут выбрать.
Если обычным пользователям не нужен в лейблах видимый текст, его можно добавить только для скринридеров: заверните текстовое содержимое лейбла в span c классом .visually-hidden.
Div вместо Button
Последняя проблема — див вместо кнопки. Визуально никакой разницы, и по поведению тоже — по клику на «Заказать» происходит отправка формы, но для скринридера разница будет значительной: div — не интерактивный элемент, поэтому его не будет в роторе:
Если просто читать страницу сверху вниз, кнопка будет озвучена как обычный текст:

И на неё нельзя будет попасть по табу. Даже если пользователь скринридера умудрится заполнить форму, он просто не сможет её отправить.
Можно добавить диву атрибуты, чтобы браузер начал считать его кнопкой, но воспроизвести полноценное поведение обычной кнопки будет сложно, да и зачем, если можно сразу взять button?

Скринридер распознает кнопку как интерактивный элемент и озвучит это, покажет её в роторе, на неё можно будет перейти по табу, а нажав Enter или Пробел — отправить форму.
Если вам где-то на странице нужна кнопка — просто используйте button. Если по клику на элемент происходит переход на другую страницу — используйте ссылку. Даже если по макету ссылка выглядит как кнопка, возьмите ссылку и стилизуйте её под кнопку с помощью CSS. Если вам требуется интерактивный элемент — это в любом случае это не span и не div, используйте более подходящие теги.
Таким образом, чтобы сделать инпуты доступными, нужно использовать теги по назначению, не скрывать их с display: none и не забывать про текстовые описания.
Для сравнения посмотрим на содержимое ротора на странице с хорошим примером:

В роторе видны все инпуты с описаниями и все состояния, есть текстовое поле и кнопка отправки формы. Уже очень неплохо, но кое-чего не хватает: непонятно что именно предлагается добавить в заказ и к чему относится выбор цветов.
Для вёрстки форм есть ещё пара тегов, которые не показываются в роторе, но они важны для правильного ориентирования в форме:
Fieldset и Legend
Когда инпутов мало, в принципе, даже по списку инпутов в роторе можно понять какие варианты выбора есть. Но формы могут быть очень разными и очень сложными, и тогда будет полезно группировать инпуты, а больших формах это совершенно необходимо.
Для группировки инпутов есть тег fieldset, а для именования группы — legend. Их использование выглядит примерно так:
<fieldset>
<legend>Сорта яблок</legend>
<label>
<input
type="radio"
name="type"
value="gala"
>
Гала
</label>
<label>
<input
type="radio"
name="type"
value="golden"
>
Голден
</label>
</fieldset>
У fieldset и legend могут быть проблемы со стилизацией в разных браузерах, но это совершенно не повод от них отказываться, все проблемы решаемы, а отсутствие в форме fieldset и legend может создать сложности пользователям скринридеров.
Что будет, если не использовать их вообще? Это можно проверить на странице с плохим примером. Поля не будут явно сгруппированы, а имя группы прочитается как обычный текст:

Если перед набором инпутов совсем не будет текста, у пользователя скринридера не будет совершенно никакой информации о том, что и зачем ему нужно сделать с этими инпутами. Если пролистать все инпуты, скринридер сразу перейдёт к следующему элементу формы никак не обозначив, что это была группа.
Скринридер не умеет делать такие выводы просто на основании того, что мы положили рядом несколько инпутов и текст. Чтобы помочь ему правильно понимать структуру формы, нужно использовать соответствующие теги.
Что увидит скринридер в форме c fieldset и legend, можно проверить на странице с хорошим примером. Скринридер находит группу и сообщает её название:

Озвучивает, что сейчас мы находимся внутри группы:

А когда мы выходим из группы, скринридер явно сообщает какую именно группу мы покидаем:

Использование fieldset и legend помогает не только оценить размеры формы, понять, сколько полей нужно заполнить для решения своей задачи, но и уравнивает возможности пользователей. Зрячие увидят заголовок группы и рамки, ограничивающие группы полей и инпутов, пользователи скринридеров — услышат информацию о группе и инпутах внутри неё.
Если форма на сайте сверстана правильно, пользователь скринридера сможет купить билет, отправить письмо или оформить заказ не имея ни малейшего представления как выглядит форма на странице.
Narrator не озвучивает явно группы (или я не нашла где это настроить), но без fieldset он неправильно определяет количество инпутов в группе: например, считает выбор цветов и веса упаковки одной группой. Если fieldset есть, при выборе инпутов Narrator озвучивает название группы, заданное в legend.
fieldset позволяет группировать только инпуты, но на страницах часто можно встретить и другой сгруппированный контент — картинки в галерее, ссылки в навигации, шаги в туториалах. Для этих целей можно использовать списки. Как к ним относятся скринридеры?
Списки
Списки верстаются с помощью ol, ul или dl. Смысл списка — объединение однотипных элементов.
В страницах с примерами много списков, например, в рецептах это ингредиенты и процесс:

Попробуем прочитать верхний список на странице с плохим примером, там он вместо ol и li свёрстан дивами:

Скринридер будет просто читать текст сверху вниз никак не связывая элементы друг с другом.
Сравним с хорошим примером. Скринридер сразу озвучит список и сообщит сколько в нём элементов:

Для каждого пункта списка он зачитает всё текстовое содержимое, то есть не только ингредиент, но и его количество, а также покажет в каком месте списка мы находимся:

И озвучит выход из списка:

Для нумерованного списка, у которого не скрыта нумерация, может показать номер позиции или озвучить буллет:

Это поведение может различаться для разных браузеров.
Когда мы видим список чего-либо на странице, мы можем понять длинный он или короткий, увидеть, в каком месте списка находится нужный нам элемент. В случае с рецептом это поможет оценить его сложность и понять сколько шагов осталось до финиша, если мы таки начали варить компот.
Если мы используем для вёрстки списков правильные теги, пользователи скринридера смогут получить ту же информацию просто прослушав рецепт. Если же верстать списки дивами, для пользователей скринридера они окажутся простынёй бессвязного текста. Чтобы сделать списки доступными, используйте правильные теги.
Ещё скринридер умеет озвучивать ссылки и картинки.
Ссылки
Как посмотреть какие ссылки нашёл скринридер:
- Narrator:
ЭД + F7 - VoiceOver: откройте ротор с
VO + Uи стрелками пролистайте до раздела со ссылками
Ротор показывает все ссылки на странице, какие ему удалось найти:

Пользуясь таким списком можно, например, на сайте с новостями прочитать все ссылки на статьи и сразу перейти в нужную.
Но это скрин со страницы с плохом примером, и если сопоставить его с содержимым страницы, можно заметить, что части ссылок нет. Например, нет крайних ссылок из нижней навигации:

Если попытаться прочитать непосредственно отсутствующие ссылки, скринридер покажет такое:

Это ссылка «Наверх».

А это — ссылка на репозиторий.
Если в ссылке нет текста, её не будет в роторе. И даже перейдя на саму ссылку, пользователь скринридера сможет получить информацию только из адреса ссылки, что в случае ссылки «Наверх», как мы видим, не работает — там покажется текущая страница вместо #top.
Narrator в роторе показывает все ссылки, но ссылки без текста будут в виде полного адреса.
Для решения проблемы достаточно добавить в ссылки текст. В хорошем примере для ссылки «Наверх» это сделано спаном с классом .visually-hidden, для ссылки на репозиторий — атрибутом aria-label.
Оба способа работают, ссылки отображаются в роторе:

Способ с .visually-hidden мне нравится немного больше, потому что такая ссылка будет видна если не будет стилей, содержимое aria-label в этом случае не отобразится.
Ещё раз: если по клику на элемент происходит действие на текущей странице либо отправка формы — используйте button. Если клик по элементу уводит на другую страницу — это ссылка. Конечно, можно навешать событий на див и сделать вид, что он ссылка или кнопка, но для пользователей скринридеров такие элементы с высокой степенью вероятности могут оказаться недоступными, используйте правильные теги.
Картинки
Как посмотреть какие картинки доступны для скринридера:
- Narrator:
ЭД + F5, в выпадушке выберите «Все», в этом списке будет всё, что нашёл скринридер, в том числе и картинки. Отдельного раздела с ними нет - VoiceOver: откройте ротор с
VO + Uи стрелками пролистайте до раздела с картинками
В качестве описания картинок скринридер использует содержимое атрибута alt. Картинки, у которых есть описание, отобразятся в роторе:

И будут озвучены при последовательном чтении страницы:

Эти скрины сделаны в хорошем примере. В плохом, как обычно, всё сломано: у картинки нет атрибута alt.
Firefox просто скажет что это картинка без каких-либо описаний и дополнений, а вот хром не только сообщит, что у картинки нет описания, но и предложит открыть контекстное меню, чтобы его получить:

А в нём будет предложено получить описание из Google, такая опция есть только при запущенном VoiceOver. Полученное описание появится в том же попапе:

Описание на английском, но это всё же лучше, чем ничего.
Narrator также предлагает получить описание картинки, только от Microsoft, нажав ЭД + Ctrl + D. Таким же образом можно получить заголовок страницы по ссылке. Как и в VoiceOver, полученный текст не переводится на язык документа.
Отсутствие alt является ошибкой (и это покажет валидатор), потому что alt обязательный атрибут, он должен быть у всех картинок на странице.
Если картинка несёт чисто декоративные функции, лучше всего её вставить через CSS, но если такой возможности нет — добавьте ей пустой alt. Это будет означать, что картинка не содержит полезной информации и вставлена исключительно для красоты. Скринридеры такие изображения полностью игнорируют и не показывают ни в роторе, ни при последовательном чтении страницы.
Для всех остальных картинок постарайтесь добавлять осмысленный alt. Лучше всего, чтобы там было именно описание изображения, а не куски из окружающего текста, тогда alt действительно будет полезен.
Выводы
Иногда нам лень верстать семантично и использовать правильные теги, потому что ну какая разница, добавим стили и всё будет выглядеть как надо, но для пользователей скринридеров плохая разметка может стать серьёзной проблемой. Семантичная разметка позволит таким пользователям правильно услышать страницу и воспользоваться сайтом для решения своих задач.
Тема доступности — большая и сложная. Помимо семантической разметки она также включает в себя использование контрастных цветовых схем, упрощение текстов для улучшения восприятия, правильную разметку всплывающих окон и меню и многое другое. Но даже не погружаясь глубоко в эту тему, можно сделать достаточно много просто используя теги по назначению.
Так что если у вас возникала мысль «зачем нам столько разных тегов?» — в том числе, вот за этим, они помогают программам экранного доступа правильно озвучивать страницу. А кроме того, используя теги по назначению, гораздо удобнее верстать. Например, вот так выглядит в коде конец страницы в плохом примере и в хорошем:


В хорошем примере сразу видно где какой тег закрылся, в плохом же можно понять только то, что закрылся див, открытый где-то выше. Если в каком-то месте потеряется закрывающий див или наоборот, заведётся лишний открывающий — страница развалится, а если все теги выглядят одинаково — такую ошибку легко сделать просто по невнимательности.
validator.w3.org/nu/ поможет обнаружить потерявшиеся теги, а использование разнообразных тегов снизит риск возникновения такой проблемы.
Кстати, самый простой способ увидеть структуру страницы (и косвенно оценить доступность) — это посмотреть на неё без стилей. Например, вот так выглядит на разных версиях раздел с рецептами:


Плохая версия без стилей похожа на поток сознания, в то время как хорошую всё ещё можно без проблем прочитать.
Надеюсь, статья поможет вам внимательней относиться к тегам и лучше понимать почему это важно.
Увидеть больше рекомендаций по разметке с примерами кода можно на Веблайнд. Почитать про доступность — в блоге Веб-стандартов.
Upd. от 9.09.2020: как заскринить попапы скринридера? Это нетривиальная задача, потому что при нажатии хоткеев фокус читалки уходит на новое действие. Содержимое попапа с текущим текстом меняется, ротор мгновенно закрывается. Я использовала Monosnap, чтобы записать видео работы со скринридером, сохраняла его в GIF с частотой 1-3 кадра в секунду (чтобы в итоговом файле было как можно меньше одинаковых кадров) и потом из этой гифки в фотошопе вырезала нужный попап. Чтобы содержимое страницы не просвечивалось под попапом, контент можно скрыть с помощью opacity: 0 либо сделать внизу страницы большую белую область и размещать её под попапом прокручивая страницу.
- Метки:
- доступность